5 The plot data
5.1 Datasets
A dataset is a table with (pairs of) values. Each dataset gets a number, according to its appearance, and
can be given an additional name (see COMMAND SETNAME).
Each dataset is de�ned by a block started by a line
N= . . .
and ended by any of these lines
FINISH
COMMAND INCLUDE
COMMAND INFITS
(see Sect. 5.3).
The block consists of the data and COMMANDs. Most of the COMMANDs can address another
dataset (if it already exists at that point), if the COMMAND ends with DATASET=dataset where dataset
is the number or name of that set.
5.2 Headline and plot attributes
-
N=m SYMBOL=n SIZE=x:x PEN=j XYTABLE COLOR=i
-
This is a typical headline of a dataset block. The �rst two characters \N=" are mandatory.
All other parameters can be in arbitrary order. If absent, default values are applied.
-
N=m
-
Set the number m of following data points (i.e. pairs of x;y values) or set N =? to read
all data until FINISH is encountered. Note: In case an explicit m is given, there is no
need for a FINISH line.
-
SYMBOL=n
-
(also: PLOTSYMBOL=n) Set the symbol for this dataset (default is 5, see Fig. 5). If
SYMBOL=0, the set will not be plotted but it can be addressed (DATASET=dataset,
calculations, error bars etc.).
-
SIZE = x:x
-
(also SYMBOLSIZE) Set the symbol size (default: 0.3). If the size is negative, the area
enclosed by the curve is �lled (for symbols which draw a line), or the symbols are �lled
(in case of �llable symbols, see Appendix C).
-
HATCHED
-
acts like negative size, but applies a hatched �lling of areas (cf. Sect. 3.4.3 for
details).
-
PEN = j
-
Set the line width (default: 1 or the value set in PENDEF).
-
COLOR = i
-
Set the color (i = 0:::9; default: 1 or the value set in DEFAULTCOLOR). If SYMBOL=40
(false color) is set, COLOR refers to the color table (1 to 5):
1= greyscale, 2= blackbody, 3= blue-black-red, 4= blue-white-red, 5= rainbow (see
Fig. 4). Also see nNCOLORSTEP if needed (Sect. 3.4.1).
� Data formats: WRplot can read di�erent formats of datasets { tables, sorted pairs and line-wise
x and y values:
-
XYTABLE
-
Set this parameter to expect a normal table with data in columns. If XYTABLE is not
set, WRplot expects a di�erent (default) format of the data: First a line of x values,
followed by a line of the same number of y values (the number of values per line is
irrelevant, it just needs to be the same to allocate the x;y pairs), then a line of x values
etc.
-
FLEX-XYTABLE
-
Set (alternatively to XYTABLE and SELECT) to expect the data in one line as ordered
pairs, i.e. x1 y1 x2 y2:::.
-
SELECT 1>:2>
-
Set the ID of the columns of the data table (only if XYTABLE is set) that shall be used
as x values (n1) and y values (n2); default: 1 : 2. Bonus: If one of the ni is set to �1
(i.e. SELECT= �1 : 1), the values are sequentially numbered. Attention: There is no
check if the given column ID is present in the data table! If it's not, WRplot will probably
plot nonsense.
5.3 Data tables
Data tables can either be written inside the block (between N= and FINISH), be included from external
�les, or mixed. In the mixed case the data inside the block are read �rst, followed by the external
ones.
-
FINISH
-
Finish a dataset. Alternatively to FINISH it can also be closed by including external
�les: COMMAND INCLUDE or COMMAND INFITS. The data table must be between the
headline (N=? . . . ) and the FINISH command.
-
COMMAND APPEND
- dataset
Append the data of dataset to the current dataset.
-
COMMAND INCLUDE
- <�lename: string>
Read the data of this dataset from the external �le �lename. Note: The chosen data format (see
above) applies here. Recursive including is allowed (i.e. the included �le may include another
�le).
There are three basic ways the data in the included �le may look:
-
Raw dataset:
- The �le just contains the data points, i.e. pairs of wavelength and �ux.
-
Normal WRplot �le:
- The �le is another WRplot �le with a single dataset (i.e. starting with
N=. . . ) which is included.
-
Normal plot �le:
- Like in the second case but with multiple datasets. Use the keyword
INCKEY=string (cf. nINCLUDE in Sect. 3.2) to extract the dataset following the given
string or/and use the keyword DATASET=n to include the nth dataset of that �le. If both
INCKEY and DATASET=n are set, take the nth dataset following the string, instead.
This allows to extract datasets from plots with several datasets in one plot.
In any case an additional FINISH is not needed. Either the included �le has a FINISH/END or the
E-O-F of that �le is allowed as end of the dataset.
-
COMMAND INFITS:
- <Filename.�ts> [ options ]
Include a (simple!) �ts �le. There are several options but only few of them are documented so far.
The most useful usage of this command is to read one or more rows and/or columns
of a �ts �le image (i.e. spectrum). The x values are sequentially numbered 1; 2:::,
e.g.:
COMMAND INFITS filename.fits NHDU=2 ROW=7
! read the seventh row of �lename.�ts into this dataset;
COMMAND INFITS filename.fits NHDU=2 ROWS= 7 15
! read and add up the rows 7 to 15 of �lename.�ts into this dataset.
Known options:
INFO, SHORT-INFO (return information on the �ts �le); NHDU (?); NROW (?); NSTART (?); DN
(?); ROW, ROWS (read the given row(s and add them up)); BINTABLE (?); IMEXT
(?)
(taken from �htodt/science.dir/lib_wrplot_x86_X11_x64/routines.dir/in�ts.f)
5.4 COMMAND lines
Some COMMANDs are executed (or set parameters) when they are read: APPEND, X-RANGE,
Y-RANGE, SKIP, SETNAME, INCLUDE, INFITS. They cannot be skipped by IF constructions (see
below). All other COMMANDs are �rst read and put on a stack before they are applied on the complete
dataset in their order of appearance.
-
COMMAND SETNAME
- <name: string>
Set a name for the current dataset to address it (i.e. for APPEND, ARI) either by this name
or its sequential number.
-
COMMAND X-RANGE:
- 1: units> 2: units>
Ignore all points during the read-in phase, if their x coordinate is not in the interval [x1;x2].
-
COMMAND Y-RANGE:
- 1: units> 2: units>
Ignore all points during the read-in phase, if their y coordinate is not in the interval [y1;y2].
-
COMMAND X-CUT:
- 1: units> 2: units>
Delete all points of the dataset, if their x coordinate is not in the interval [x1;x2].
-
COMMAND Y-CUT:
- 1: units> 2: units>
Delete all points of the dataset, if their y coordinate is not in the interval [y1;y2].
-
COMMAND X-OMIT:
- 1: units> 2: units>
Delete all points of the dataset, if their x coordinate is in the interval [x1;x2] (negation of
X-CUT).
-
COMMAND Y-OMIT:
- 1: units> 2: units>
Delete all points of the dataset, if their y coordinate is in the interval [y1;y2] (negation of
Y-CUT).
-
COMMAND XY-SWAP
-
Swap the x and y values of the current dataset.
-
COMMAND WAVECAL
- <dataset i>
The y values of the current dataset are taken as x values for dataset i (i.e. it must already
exist at that point). This requires both sets to have identical x values before.
Especially for wavelength calibration the current dataset may have a di�erent set of x
values, i.e. just a few support points of calibration lines. They need to be in monotonic
order, at least. COMMAND WAVECAL then interpolates between them (splines) and/or
extrapolates outside (linear with the �rst/last two values of the table) to obtain the set of x
values as needed for dataset i.
-
COMMAND SKIP
-
Skip the current (or the last i) dataset(s), i.e. do not plot it/them and delete it/them after all
COMMANDs were performed. Note: The sequential ID for following datasets is reduced by
1 (or i), too.
-
COMMAND EXPAND
- <N> [<�1: units> <�2: units>]
or
-
COMMAND EXPAND-SPLINE
- <N> [<�1: units> <�2: units>]
Expand the dataset by N points (between �1 and �2 if they are set) by linear interpolation
of cubic spline interpolation, respectively.
-
COMMAND INSERT
- <�1: units>
Insert a point at x = �1 (always by linear interpolation between two existing points).
-
COMMAND HLYMAN
- parameter (also HLYMANA)
Apply corrections for interstellar absorption by hydrogen Lyman lines (from Ly� to Ly20).
The format of x;y data is mandatory: x values are expected to be wavelengths in Å and y
is expected to be the linear �ux (i.e. in erg s�1 cm�2 �1).
This command corrects the observation by absorption (removes it); to add the absorption
to a model �ux, one needs COLDENS or EBV as negative value. In case EBV is speci�ed,
this is converted into the column density as NH = 3:8E21 � EB�V (?).
By default, HLYMAN uses the formalism from ? which accounts only for the damping
(i.e. Lorentzian) pro�les but no Doppler cores. However, if one of the parameters T and/or
VTURB is speci�ed, HLYMAN applies Voigt pro�les with the according Doppler velocity.
The parameters consist of pairs \keyword = value"; allowed keywords are:
|
|
| Parameter | Description |
|
|
|
|
| EBV=x:x | Color excess EB�V, in magnitudes |
| COLDENS=x:x | Column density of H-atoms per cm2 (NH) |
| VRAD=x:x | Radial velocity, in km/s |
| T=x:x | Temperature in Kelvin; to additionally account for Doppler |
| | broadening with the thermal velocity (Maxwellian?) |
| VTURB=x:x | Turbulence velocity in km/s causing additional |
| | Doppler broadening |
|
|
| |
One of the parameters (EBV or COLDENS) is mandatory.
Example:
COMMAND HLYMANA EBV=0.2 VRAD=255.
For compatibility with older syntax, one can use numerical parameters without keyword (but this is
not recommended):
- only one parameter is interpreted as the value of EBV
- two numerical parameters are interpreted as EBV and VRAD
-
COMMAND ISMLINE
- parameter
Correction or simulation of an interstellar line; the command is similar to HLYMAN, but now for an
arbitrary line which is fully speci�ed by the command. This command corrects the observation by
absorption (removes it); to add the absorption to a model �ux, one has to specify COLDENS as
negative value.
The following parameters are mandatory:
|
| | Parameter | Description |
|
|
|
| | COLDENS = x:x | Column density of the absorbing atoms per cm2 |
| L0 = x:x | Central wavelength of the ISM line in Å |
| GAMM = x:x | Damping constant for this transition in s�1 |
| F = x:x | Oscillator strength |
|
| | |
|
If the following three parameters are also speci�ed, the synthetic pro�le will also include a Doppler
core and produce a Voigt pro�le:
|
| | Parameter | Description |
|
|
|
| | T = x:x | Temperature in Kelvin; additionally accounts for Doppler |
| | broadening with the thermal velocity |
| A = x:x | Atomic weight in Atomic Mass Units |
| VTURB = x:x | Turbulence velocity in km/s causing additional Doppler broadening |
|
| | Further optional parameter:
| | VRAD = x:x | Radial velocity in km/s |
|
| | |
|
-
COMMAND REDDENING
- (B�V): real> [law] [RV]
Apply a correction for interstellar reddening. In contrast to HLYMAN, both the x and y values are
now expected to be logarithmic (log[�=Å] and log f , respectively). The x values must be in
monotonic order and are automatically expanded to 1000 points if there are less. If no law is given,
the default is used (?).
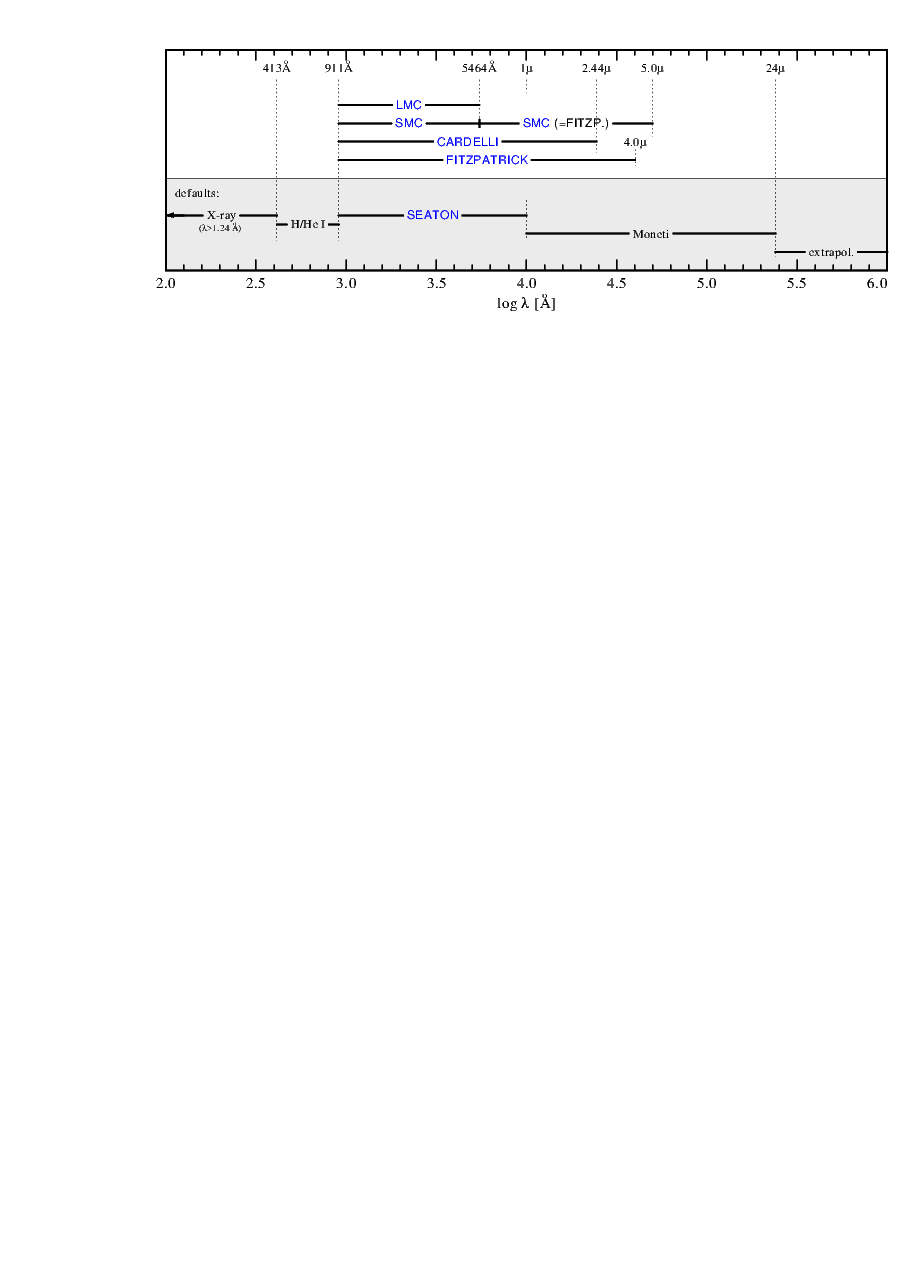
| Table 4: | Reddening laws as for the di�erent Keyword |
|
|
|
|
|
|
|
| | Keyword | Ref.a | default RV | Comment |
|
|
|
| | SEATON | S, N | 3:1 | default in the range 911 Å { 1 �m; |
| (or none) | | | established by Seaton for � < 3700 Å, |
| | | | and augmented by Nandy et al. for 3500 < � < 10000 Å |
| CARDELLI | C | 3:1 | established for 1000 Å { 3.33 �m, used here for 911 Å { 2.44 �m |
| FITZPATRICK | F | 3:1 | established from 1150 Å { 5 �m, used here for 911 Å { 4 �m |
| LMC | H | 3:2 (�xed) | special for the LMC |
| SMC | H | 2:7 | RV from ? |
| | | | with RV = 3:2 it becomes the LMC law |
| SMC_BAR | G | 2:74 | for � < 3000 Å; to the red: FITZPATRICK with RV = 2:74 |
| | | | for � > 5 �m it follows ? |
|
|
|
| | |
a References: C: ?; F: ?; G: ?; H: ?; N: ? S: ? |
Note: RV = AV=EB�V, where AV is the extinction in the V band. All reddening laws are extended
towards the red end (outside their \range") according to a table from ?, above � > 24 �m an
extrapolation / ��2 is extended.
In the X-ray regime (� = 1:24 � 413 Å) the absorption is calculated according to Table 2 of ?. The
edges in this wavelength range arise due to the K-shell absorption of di�erent elements (a solar
composition is assumed). In the range � = 413 � 504 Å (the He i edge) these tabulated polynoms
are extrapolated.
In the range of � = 504 � 911 Å, i.e. between the Lyman edge of hydrogen and the He i edge, only
the opacity of H i is considered in the same way as in the PoWR code (including the Gaunt
factor).
-
COMMAND CONVOL:
- <Keyword> <C>
Convolve the dataset by the function given as keyword and parameter C:
|
|
|
|
|
| | Keyword | Kernel function | Parameter |
|
|
| | GAUSS | Gaussian | FWHM |
| BOX (or KASTEN) | box pro�le | half box width |
| ROT[ATION] | half ellipse1 | ��rot = �3rot=c |
| MACRO-RT | radial-tangential | ��macro = �3macro=c |
| | macroturbulence pro�le2 |
|
|
| | |
1 additional parameter (optional): limb-darkening coe�cient BETA=� (?) 2 ? |
Example (see also the example plots):
COMMAND CONVOL ROT=0.2 BETA=1.5
-
COMMAND BINNING
- w
This command requires the dataset to be monotonic in x. Starting with the �rst value, all points
with x values di�ering � w (8j with xi + w > xi+j) are averaged. Each new point (xi0;yi0) is the
arithmetic mean of all xi+j;yi+j that were averaged.
-
COMMAND X+
- : units> (also COMMAND XADD or COMMAND XOFFSET)
Add the constant A to the x values of the dataset, i.e. shift the x coordinate by A. Note: Between
X+ and A there must be a blank (this applies to the rest, too!).
-
COMMAND X-
- : units> (also COMMAND XSUB)
Subract the constant A from the x values of the dataset.
-
COMMAND Y+
- : units> (also COMMAND YADD or COMMAND YOFFSET)
Add the constant A to the y values of the dataset.
-
COMMAND Y-
- : units> (also COMMAND YSUB)
Subract the constant A from the y values of the dataset.
-
COMMAND X*
- : units> (also COMMAND XMULT)
Multiply the constant A to the x values of the dataset.
-
COMMAND X/
- : units> (also COMMAND XDIV)
Divide the x values of the dataset by the constant A.
-
COMMAND Y*
- : units> (also COMMAND YMULT)
Multiply the constant A to the y values of the dataset.
-
COMMAND Y/
- : units> (also COMMAND YDIV)
Divide the y values of the dataset by the constant A.
-
Note:
- Instead of a constant A one can also write X or Y in the above COMMANDs, i.e. to multiply the
�ux by the wavelength.
-
COMMAND XINV
- or COMMAND 1/X
Invert the x coordinates of the dataset.
-
COMMAND YINV
- or COMMAND 1/Y
Invert the y coordinates of the dataset.
-
COMMAND XDEX
- or COMMAND 10��X
Delogarithmize (un-log) the x values of the dataset.
-
COMMAND YDEX
- or COMMAND 10��Y
Delogarithmize (un-log) the y values of the dataset.
-
COMMAND XLOG
- or COMMAND LOG(X)
Logarithmize the x values of the dataset.
-
COMMAND YLOG
- or COMMAND LOG(Y)
Logarithmize the y values of the dataset.
-
COMMAND XMIN = x.x
-
Set all x values of the dataset with x �x.x to that value. In an analogous way the following three
COMMANDs exist:
-
COMMAND XMAX = x.x
-
-
COMMAND YMIN = x.x
-
-
COMMAND YMAX = x.x
-
-
COMMAND Y-NORM
- 1: units> 1: units>
or
-
COMMAND Y-NORM*
- 1: units> 1: units>
Normalize the curve (y values) by the given point (x1;y1). This command �nds the
interval around x and adjusts the y values of the dataset by addition (or multiplication,
respectively) such, that the given point (x1;y1) becomes part of the curve, i.e. normalizes the
curve.
-
COMMAND SIGN(X)
-
Replace the x values by �1:; 0:; +1:, according to the signum function.
-
COMMAND SIGN(Y)
-
Replace the y values by �1:; 0:; +1:, according to the signum function.
-
COMMAND X-INC
-
Delete all points of the dataset if their x values are not monotonically increasing. This can help to
work with imported data, i.e. IUE data, that do not necessarily follow the \strict german purity laws
for nice spectra". Certain COMMANDs (like CONVOL) need monotonically sorted x
values.
-
COMMAND ARI
- <dataset 1> <operator> <dataset 2> [KEEP_X1]
Execute the operation given as operator (+, -, �, /) on the y values of the given datasets. The result
is saved in dataset 1. If the x values are identical for both datasets, the y values are assigned
pair-wise, else they are interpolated in the overlapping region. If either x set is nonmonotonic the
command returns an Error message.
The optional parameter KEEP_X1 disables the interpolation of x data, i.e. the y values are only
calculated at these supporting points. The saved values for dataset 1 are only at these points,
then.
-
COMMAND STRIP
- <y1: units> <y2: units>
Set the strip (between y1 and y2) in which the false-color representation is plotted. The x values
are taken from the dataset, i.e.
N=2 XYTABLE SYMBOL=40 SELECT=1:1 COLOR=5
COMMAND STRIP= 0.5 1
COMMAND EXPAND 1000
0
2
FINISH
|
plots a rainbow colored strip (COLOR 5) between x = [0; 2] and y = [0:5; 1].
-
COMMAND XERROR
- <dataset n> <type: PLUSMINUS/MINMAX>
Assign the dataset n as error data in x to the current dataset, i.e. the dataset n must be
de�ned before the current one. The mandatory parameter type sets the type of error
data:
relative to the data point (PLUSMINUS); or absolute (MINMAX).
Note: The dataset n must have SYMBOL=0, i.e. not be plotted directly, and must either consist of
a single pair of data (to have that error bar for the whole dataset); or have the same number of
data points as the current set (individual error bars for each x value). The style (COLOR, PEN,
SIZE) of the error bars is taken from the headerline of the dataset n. SIZE characterizes the size of
the error bar's footer (the small perpendicular bars). Note: To get error bars in both directions,
i.e. x�0:7+0:5, the dataset n must contain both numbers as two columns, e.g. 0:5 as x value and
�0:7 as y value.
-
COMMAND YERROR
- <n> <type>
Like XERROR, but for errors in y (to have independent error bars for either/both uncertainties).
-
COMMAND MERGE
- <dataset1> <dataset2>
Merge two (ordered) datasets into dataset1. In overlapping intervals the arithmetic mean
is taken (by interpolation where needed, i.e. if the x values are not identical). This
command is especially useful to merge overlapping spectra, like the di�erent Echelle
orders.
-
COMMAND SORT
- [INV] [JOIN]
Sort the dataset such, that the x values will be in monotonic order. With the optional parameter
INV given, the dataset is sorted in a falling sequence. With the optional parameter JOIN given, the
dataset becomes strictly monotonic. Entries with identical x values are joined into one entry, with
the y value set to their arithmetic mean. This command is useful in preparing datasets for
operations that require a monotonic order.
-
COMMAND WRITE
- [FILE=<�lename: string>]
Write the current dataset (in its state at the line COMMAND WRITE is given) as an XYTABLE into
the given �le (overwrites an existing �le). If no FILE=�lename is given, the output �le
will be named WRPLOT_DATASETn.DAT, where n is the sequential number of that
dataset.
-
COMMAND kasdef-kommando, i.e. IF, ELSE, ENDIF
-
Furthermore, many commands described in the KASDEF sections can be placed into the
COMMAND block, excluding those which plot/write text (from ARR to LUN and the TEXT options).
But commands that handle variables, i.e. COMMAND CALC, conditional constructions
(IF, ELSE etc.), DO loops, ECHO, GOTO and LABEL are allowed, i.e. most of Sect.
3.3.
5.5 COMMAND-Functions
COMMAND CF-... ...
WRplot has some Command-Functions. These functions calculate di�erent things and save the
result in variables that can be used in following COMMANDs or KASDEFs. Currently there
are:
-
COMMAND CF-YEXT
- <�: units> <VAR>
Interpolate the y value at x = � and save it in the variable VAR. If SYMBOL=6 or 7, the
interpolation will be splines, else linear.
-
COMMAND CF-YMAX
- <XVAR> <YVAR>
Find the point with y = max(ydataset) and save that point's coordinates in variables XVAR,
YVAR.
-
COMMAND CF-YMIN
- <XVAR> <YVAR>
Find the point with y = min(ydataset) and save that point's coordinates in variables XVAR,
YVAR. Note: To �nd the smallest/largest value of x, use COMMAND XY-SWAP, COMMAND
CF-YMIN/MAX, COMMAND XY-SWAP.
-
COMMAND CF-YSUM
- <VAR>
Sum up all y values of the dataset and save the result in the variable VAR.
-
COMMAND CF-INT
- <VAR> [FROM 1: units> TO 2: units>]
Integrate the tabulated function and save the result in the variable VAR. The function just
needs to be monotonic. By default the integration is done over all x values, however, one
can set the integration limits x1 and x2 to integrate VAR=R
x1x2y(x)dx (both must be within
the range of x values, i.e. no extrapolation).
-
COMMAND CF-LINREG
- [x1 y1 x2 y2 a b aerr berr]
Fit the dataset by a linear regression curve yr = a + bx. Note: One can also �t power laws
if the dataset is logarithmic. There are up to eight variables for CF-LINREG, which can get
their values by this COMMAND function. Their meaning is:
x1 = smallest x value of the dataset
y1 = value of yr at that point
x2 = largest x value of the dataset
y2 = value of yr at that point
These four variables are most helpful to plot a regression curve using
nLINUN $x1 $y1 $x2 $y2 0 0
though the data points.
Further optional variables contain the values of:
a = coe�cient a of the above regression function
b = coe�cient b of the above regression function
aerr = formal uncertainty (1�) of a
berr = formal uncertainty (1�) of b
If the dataset has error bars in y (i.e. YERROR has been used), the points are weighted
accordingly. Note that the coe�cients a;b are calculated by di�erent means if error bars
are present (cf. Numerical Recipes), especially the formal errors aerr;berr can be smaller if
the data have error bars.
All these parameters are also printed in the command window/Terminal.
-
COMMAND CF-NDATA
- <VAR>
Write the number of data points (i.e. number of (x;y) pairs) in the variable VAR.